
Proper design and security are key elements of data lake organization
Design patterns of a business’s data lake are the foundation of future development and operations. Security is necessary to enforce not only compliance, but also to keep the lake from becoming a "data swamp" or a collection of unorganized data within the data lake.
Design
The overall design of a data lake is vital to its success. Coupled with security and the right organization processes, the data lake will provide valuable new insights; ultimately providing more tools to executives for making strategic decisions.
Nonetheless, if a data lake is designed poorly, it can quickly become a mess of raw data with no efficient way for discovery or smooth acquisition, while increasing extracting, transforming and loading (ETL) development time and ultimately limiting success of the data lake.
The primary design effort should be focused on the storage hierarchy design and how data will flow from one directory to the next. Though this is a simple concept, as laid out below, it will set up the entire foundation of how a data lake is leveraged from the data ingestion layer to the data access layer.
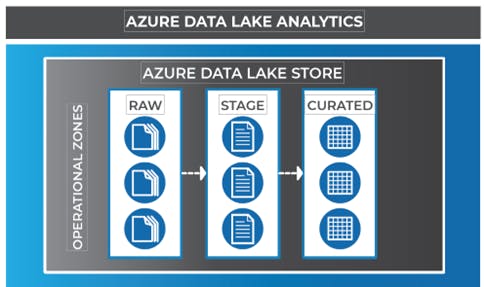
Data lake zones
Operational zones
Raw zone: This is the first area in the data lake where data is landed and stored indefinitely in its native raw format. The data will live here until it is operationalized. Operationalism occurs once value has been identified by the business, which does not occur until a measurement has been defined. The purpose of this area is to keep source data in its raw and unaggregated format. An example would capture social media data before knowing how it will be used. Access to this area should be restricted from most of the business. Transformations should not occur when ingesting into the RAW zone but rather the data should be moved from source systems to the raw zone as quickly and efficiently as possible.
Data tagging – both automated and manual – is also included in this zone. Tagging of datasets can be stored within Azure Data Catalog. This will allow business analysts and subject matter experts to understand what data lives not only in Azure Data Lake, but Azure at large.
The folder structure for organizing data is separated by source, dataset and date ingested. Big data tools such as U-SQL allow for utilization of data across multiple folders using virtual columns in a non-iterative manner.
Stage zone: The stage zone is where data is landed for processing and before it is loaded into a Hive or U-SQL table in the curated zone. Normal operations in this zone include decompression, cleansing and aggregation. The results of these activities will often be stored in an output file. From here, the data can go two places, either to a curated table, or directly to an analytical store such as an Azure Data Warehouse, utilizing Polybase for data acquisition.
Curated zone: The curated zone, loaded into either Hive or U-SQL, contains data that has been decompressed and cleansed, and is ready for storage. Data here are exclusively separated by their own databases and are conformed and summarized. This is the primary level of access to data where security allows for self-service organization intelligence and exploratory analytics. Depending on tool selection, data may need to be extracted back to a file for consumption outside of the data lake.
The zones listed above account for the primary zones within a data lake. Apart from these zones are other supporting zones that may be required to enable deeper analytics inside the data lake.
Supporting zones
Master zone: Master data will always be trusted data and will often source from the data warehouse. This can also include archived data from a data warehouse. This data will be used to support analytics within the data lake.
Exploratory zone: This is an open area where data scientists and analysts can discover new value from the data lake. They can leverage multiple zones to find the best possible value from new data. This zone should be organized by user and project.
Transient zone: This zone acts as a temporary zone and supports ingestion of the data. A use case for this zone is that you may want to decompress data in this zone if you are moving large amounts of compressed data across networks. The data should be short lived, hence the name Transient.
Security
In a big data solution, data must be secured in transit and at rest. There must be a way to limit visibility for circumstances such as conforming to compliance standards. Azure Data Lake provides enterprise grade security in the areas of authentication, auditing and encryption.
Data access control: There are two Access Control Lists (ACLs) within Azure Data Lake: Access ACLs and Default ACLs. The Access ACL controls the security of objects within the data lake, whereas the Default ACLs are predefined settings that a child object can inherit from upon creation.
At a high level, a folder has three categories of how you can assign permissions: “owners”, “permissions” and “everyone else”. Each of which can be assigned read, write and execute permissions. You have the option to recursively apply parent permissions to all child objects within the parent.
It’s important to have the security plan laid out at inception, otherwise, as stated above, applying permissions to items is a recursive activity. Access settings such as read, write and execute can all be granted and denied through the Azure Portal for easy administration as well as automated with other tools such as PowerShell. Azure Data Lake is fully supported by Azure Active Directory for access administration.
Data security: Role Based Access Control (RBAC) can be managed through Azure Active Directory (AAD).
AAD Groups should be created based on department, function and organizational structure. It is best practice to restrict access to data on a need-to-know basis. When designing a data lake security plan, the following attributes should be taken into consideration.
- Industry-specific security: If you are working under HIPAA for patient records, it is required that users only have access to a patient’s record if it’s in conjunction with their specific role. Protected health information (PHI) may need to be scrubbed before data can be surfaced for mining and exploration. If this is the case, it could change the security plan to be more restrictive.
- Data security groups: These should align with the flow of the data through the data lake. Depending on how the data lake will be surfaced to end users and services, data will be more restricted at ingestion into the data lake and become more available as it’s curated. The data should be as explorable as possible without increasing risk.
- Application layer: Apart from data security at the data lake store level, keep in mind the applications that will be layered over the store itself.
Data encryption: Data is secured both in motion and at rest in Azure Data Lake Store (ADLS). ADLS manages data encryption, decryption and placement of the data automatically. ADLS also offers functionality to allow a data lake administrator to manage encryption.
Azure Data Lake uses a master encryption key, which is stored in Azure Key Vault, to encrypt and decrypt data. Managing the keys yourself provides some additional flexibility, but unless there is a strong reason to do so, leave the encryption to the data lake service to manage. If you choose to manage your own keys, and accidentally delete or lose them, the data in ADLS cannot be decrypted unless you have a backup of the keys.
- Master Encryption Key (MEK): The ADLS Master Encryption Key stored in Azure Key Vault
- Data Encryption Key (DEK): Encrypted by the MEK. Generates the BEKs for the data.
- Block Encryption Key (BEK): Unique encryption keys generated for each block of data associated with an ADLS data file. The BEK is what’s used to decrypt the actual data.
How we can help
As your business continues to develop its data lake, the design, organization and security of the data lake are vital to its success. The design patterns of your business’s data lake create the foundation for future development and operations so it’s essential to fully understand the storage hierarchy design of your data lake and how data will flow from one directory to the next when developing.
At Baker Tilly, we work with you to set up the foundation of the data lake, from the operational and supporting zones to limiting data visibility to meet compliance standards, allowing you to leverage incoming data effectively and efficiently to propel your business forwards. To learn more about how Baker Tilly can help with designing and securing your data lake, contact one of our professionals.
